📅 最后更新:2026年5月11日
✅ 审核:有道翻译编辑团队
- 千万别乱点F5:卡在99%通常说明“翻译已完成,但排版回写失败”。此时直接按 F5 刷新网页,极大概率会导致翻译失败且白白扣除你的字符额度/翻译次数。
- 紧急破局法:如果是网页端,按
F12打开开发者工具,看 Network 选项卡是否有红色报错(通常是504超时)。如果有,说明服务器已断开,只能重新上传;如果一直在pending,请耐心再等 5 分钟。 - 根治断流方案:放弃网页版的玄学网络连接!对于超过 10MB 或包含大量图表的文献,强烈建议直接使用有道翻译电脑版,客户端的底层断点续传能力远超浏览器,几乎能根绝 99% 卡死的问题。
昨晚凌晨一点,我的一位正准备赶着交 SCI 论文初稿的师弟在微信上绝望地找我:“哥,我上传了一份 60 页的全英文学术 PDF 到有道去翻译,进度条在 99% 已经卡了整整半个小时了。我现在是该刷新,还是继续等?”
相信所有用过机器翻译处理长文档的职场人和科研狗,都被这个“永远的 99%”折磨过。眼看着马上就要大功告成,进度条却像死机了一样纹丝不动。你不敢关网页,怕白白浪费了几万字的付费额度;你也不敢刷新,怕一切又要重头再来。
今天,我不说那些“检查网络”、“重启电脑”的废话。我将从机器翻译底层的“文本抽取与版式重构”逻辑出发,彻底扒光有道文档翻译卡在 99% 的核心原因,并给你一套亲测有效的急救与防坑指南。
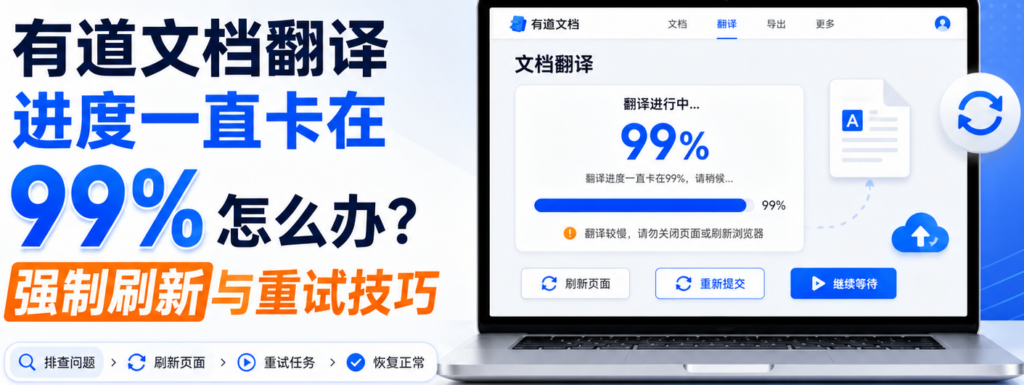
一、 核心揭秘:这该死的“最后 1%”到底在干什么?
版本说明:本文基于有道翻译最新版本编写。
想要解决问题,得先搞懂机器翻译的底层流水线。为什么它不卡在 50%,偏偏卡在 99%?
当你在有道(或其他云端翻译平台)上传一份文档时,后台其实分为三个独立阶段:
- 0% – 10%(解析与 OCR 阶段):剥离原文档的格式,把 PDF 或 Word 里的所有文字、段落提取成纯文本(TXT)。如果是扫描件,这里还会调用 OCR 图像识别。
- 11% – 90%(云端 NMT 翻译阶段):神经网络大模型(NMT)接管,把提取出来的英文纯文本疯狂翻译成中文。这个过程其实非常快。
- 91% – 99%(版式重构与回写阶段):这就是导致卡死的万恶之源! 服务器需要把翻译好的中文,按照原文档的坐标、字体大小、表格边框,重新塞回去(回写),生成一个新的可供下载的文档。
为什么会在 99% 卡死? 因为中文的物理长度通常比英文短(或者德语比英文长),当原文的一个完美对齐的表格,被强行塞入翻译后的内容时,表格撑爆了;或者原 PDF 里有一个隐藏的复杂矢量图层,导致有道的排版引擎在计算坐标时陷入了“无限死循环(Loop)”。翻译其实早就做完了,它只是无法为你生成那个最终带排版的版面。
二、 急救技巧:进度卡在 99% 时,你该如何操作?
当你已经在这个画面等了超过 10 分钟,请立刻停止无意义的等待,采取以下行动。
1. 网页端的高阶“嗅探”法(防误扣额度)
绝大多数小白遇到卡顿,第一反应是点浏览器左上角的刷新按钮(F5)。这是极其危险的,这会立刻掐断浏览器与服务器的 WebSocket 握手,大概率导致当前任务报废且不退还翻译字符数。
正确姿势:
- 按下键盘上的
F12(Mac 按Option+Cmd+I)打开浏览器的开发者工具。 - 切换到 「Network(网络)」 选项卡。
- 观察里面的请求列表。如果你看到有一行叫
doc_translate_status(或类似轮询接口)的状态码显示为红色的504 Gateway Timeout或502 Bad Gateway。- 结论:别等了,有道的排版服务器已经彻底崩溃或把你的任务丢弃了。此时你可以放心大胆地按
F5强制刷新,并去“翻译记录”里查看,如果没有生成结果,通常系统稍后会自动返还额度。
- 结论:别等了,有道的排版服务器已经彻底崩溃或把你的任务丢弃了。此时你可以放心大胆地按
- 如果接口状态是
200 OK且一直在周期性闪烁(Pending)。- 结论:服务器还在苦苦计算你的复杂排版,请务必再给它 10 分钟。

- 结论:服务器还在苦苦计算你的复杂排版,请务必再给它 10 分钟。
2. 切换客户端:降维打击的稳定性
正如本文开头 TL;DR 所说,网页版极易因为你随便切了几个后台标签页,或者电脑进入息屏休眠状态,导致浏览器主动休眠了网络连接。 如果是处理关乎饭碗的正式合同、长篇财报或几十页的科研文献,千万不要在网页上玩心跳。果断下载并安装 有道翻译电脑版。PC 客户端拥有独立的后台进程和断点续传机制,即使你锁屏去吃个饭,它也会在系统底层继续维持长连接,几乎彻底杜绝了前端卡死 99% 的闹剧。
三、 防患未然:如何对文档进行“脱水”,确保 100% 顺滑翻译?
既然卡死的元凶是“复杂的排版”,那我们只要在上传前,把原文档里的那些“排版地雷”排掉,翻译速度就能起飞。这就是专业本地化人员常说的“文档预处理”。
1. 拆除 Word 中的“嵌套炸弹”
很多老外发来的 Word(.docx)文件,里面不是简单的表格,而是嵌入了完整的 Excel 工作表对象,甚至是高分辨率的 CAD 对象图。翻译引擎在抓取这些对象时极容易崩溃。
- 脱水方法:在上传有道之前,打开原文件,另存为一个新的版本。检查文档中所有异常复杂的图表,如果是纯看文字,可以考虑将复杂的流程图或嵌套表格直接截图,变成静态图片(JPEG)贴在原处。机器对静态图片的兼容性远大于可编辑对象。
2. PDF 的“展平(Flatten)”处理
这是科研圈的硬核技巧。很多 IEEE 的学术 PDF 是用 LaTeX 编译的,里面充满了复杂的隐藏图层和字体子集(Subset Fonts)。有道的解析器看到这些会直接头晕。
- 脱水方法:用 Chrome 浏览器或 Adobe Acrobat 打开这篇 PDF,然后点击 “打印” -> 打印机选择 “另存为 PDF(Microsoft Print to PDF)”。
- 原理:这个“虚拟打印”的过程,会把原本几十个复杂的代码图层,瞬间压扁合并成一个最标准的纯净版 PDF(也就是所谓的 Flatten 处理)。拿这个压扁后的 PDF 去有道翻译,速度通常能提升 3 倍以上,且极难卡死。
3. 将 PDF 降级为 Word
如果你对原文档的精美排版没有苛刻要求(只求看懂内容),最稳妥的方案是:先用 WPS 或 Acrobat 将 PDF 转换为 Word 文档,再将 Word 文档上传到有道进行翻译。 由于 Word 的 XML 结构比 PDF 的坐标系对翻译引擎友好一万倍,这种“曲线救国”的方案几乎能让 99% 卡顿绝迹。
四、 竞品对比:极度复杂的格式,有道扛不住怎么办?
有时候,你已经把预处理做到了极致,但由于文档本身的客观属性(比如几十页极其密集的双栏医学图谱),有道的版式还原引擎就是无法通过。这时候死磕有道已经没有意义。
对于极其变态的多栏排版、嵌套表格和学术公式,目前市面上不同的 AI 翻译引擎有着完全不同的处理策略。如果你不仅追求排版不卡死,更对专业名词的学术翻译精准度有极高的要求,建议你横向了解一下行业的另一个霸主。强烈建议看看这篇关于 谁更准确?有道翻译与 DeepL 翻译质量深度实战对比 的实测文章,也许在面对特定类型的长难文档时,切换工具才是最高效的“排雷”手段。
![]()
五、 高危文档翻译自检清单 (Checklist)
在上传任何大于 5MB 或超过 20 页的文档前,请对照以下问题排查一遍,告别 99% 的绝望等待:
- 运行环境选择正确了吗? -> 核心文档是否已经改用 PC 客户端而非浏览器网页版?
- 文档格式是否纯净? -> 原文件后缀名如果是老旧的
.doc,是否已另存为现代的.docx? - 是否清除了加密权限? -> PDF 如果有“禁止复制/打印”的密码保护,必须先用解密工具移除,否则 100% 翻译失败。
- 进行了虚拟打印“展平”吗? -> 包含大量插图和图表的学术 PDF,是否已经用“另存为 PDF”过滤了复杂图层?
- 分卷处理了吗? -> 对于一本 300 页的电子书,不要头铁一次性上传。用 PDF 分割工具,每次传 50 页,这是保命的底线原则。
六、 FAQ(常见问题解答)
Q1:网页卡在 99% 我强行关掉了,结果翻译次数被扣了,这能找客服申诉吗? A:可以申诉,但不一定秒回。如果你是付费会员(购买了词数包),你可以通过客户端内的意见反馈提交工单,附带上你的翻译记录时间和报错截图。后台核实到最终文件未生成(任务状态异常),通常会在 1-3 个工作日内为你退还相应额度。如果是免费赠送的额度,建议下次直接拆分成小文档翻译。
Q2:为什么纯文本的 TXT 翻译瞬间就好,带图表的 PDF 就卡成狗? A:机器翻译纯文本就如同在白纸上写字,只消耗 CPU 的计算算力。而翻译带图表的 PDF,系统需要进行高强度的页面解析:它要判断这段字是属于表格还是标题,翻译后中文变长了,还得把旁边的图片往后挪,不能遮挡。这其实是一个复杂的“智能排版”过程。一旦遇到引擎无法理解的不规则表格(比如跨了三页的联合表格),就会卡进死胡同。
Q3:我换了别人的网络和电脑,还是在这篇文档的 99% 卡住,这是为什么? A:这说明跟你的网络环境毫无关系,100% 是这篇文档本身的格式存在“毒药代码(Poison Code)”。可能是原作者用了一种极小众的排版软件(比如早期的 PageMaker 或冷门的排版插件)导出的 PDF。解决办法只有一条:用打字机模式提取纯文本,放弃原有的全部排版格式。
作者寄语:AI 翻译大模型的进步虽然神速,但文档格式处理这块“脏活累活”依然存在大量难以逾越的技术壁垒。遇到进度条卡死,不要只是徒劳地咒骂软件,懂一点“降维排版”和网络侦测的手段,你就能比别人更快地拿到完美的双语文件。




